Datasets
4 minutes

TOC Dataset
TMLR, Dataset link: https://www.kaggle.com/datasets/011af1d77cea3112779e0ea0139debab55141b1dd93d0c2524cfc68ec5be774d
The ime-Oriented Collection (TOC) dataset introduces a new benchmark about time, consisting of high-quality images sourced from social media, featuring reliable image metadata. We collected 117,815 training samples and 13,091 test samples from the Cross-View Time, mitigating various limitations in previous datasets. This dataset reflects real-world scenarios and human activities, making time-of-day estimation more applicable to potential practical applications
For more details please refer to the paper
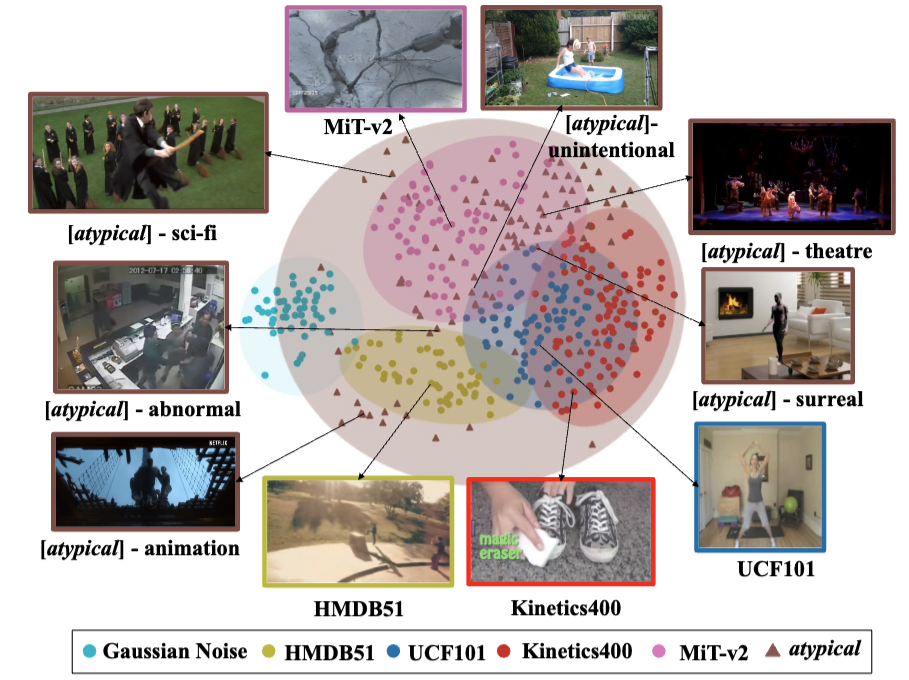
Atypical Video Dataset
BMVC, Dataset link: https://huggingface.co/datasets/mixgroup-atypical/atypical
Atypical dataset introduces the first curated video dataset capturing atypical, anomalous, and visually unconventional human activities. Sourced from real-world, synthetic, and artistic domains, it enables research into out-of-distribution video understanding. It introduces a diverse collection of short video clips that significantly diverge from everyday behavior and appearance. Unlike standard datasets that focus on typical human actions and natural scenes, Atypical emphasizes the rare, the surreal, and the unexpected—drawing from both real-life occurrences and fictional or synthetic creations.
For more details please refer to the paper

HAID Abstract Image Dataset
BMVC, Dataset link: https://huggingface.co/datasets/Froink/HAID_zipped
HAID (Hierarchical Abstraction Image Dataset) is a collection of SVG images generated from existing raster datasets at multiple levels of abstraction (controlled by the number of geometric primitives). HAID is designed to enable systematic study of how abstraction and vectorized representations affect learned visual features and downstream vision tasks.
For more details please refer to the paper

DeHate: A Holistic Hateful Video Dataset for Explicit and Implicit Hate Detection
ACMMM Datasets, Dataset link: https://github.com/yuchen-zhang-essex/DeHate
The DeHate dataset introduces the largest video dataset for hateful information detection, consisting of 6,689 videos collected from two platforms and spanning six social groups. Each video is annotated with fine-grained labels that differentiate explicit, implicit, and non-hateful content, along with segment-level localization of hate, identification of contributing modalities, and specification of the targeted groups.
For more details please refer to the paper

360+x: A Panoptic Multi-modal Scene Understanding Dataset
CVPR, Dataset link: https://x360dataset.github.io/
360+x dataset introduces a unique panoptic perspective to scene understanding, differentiating itself from existing datasets, by offering multiple viewpoints and modalities, captured from a variety of scenes.
For more details please refer to the paper

DyMVHumans: A Multi-View Video Benchmark for High-Fidelity Dynamic Human Modeling
CVPR, Dataset link: https://pku-dymvhumans.github.io/
This is a versatile human-centric dataset for high-fidelity reconstruction and rendering of dynamic human scenarios from dense multi-view videos.
For more details please refer to the paper
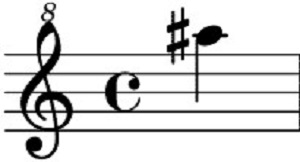
MusicMNIST: A Simple Visual-Audio Dataset for Musical Notes
Dataset link: https://doi.org/10.25500/edata.bham.00000961
A visual-audio dataset consisting sheet music images and their corresponding audio played on a range of pianos. There are 88 ground truth sheet music images which are of dimensions 162x300, 1,948 training audio files, and 516 testing audio files. The audio files have 764 frames when in Mel spectrogram representation. The dataset also contains annotations files to align the audio files to their correct ground truths and determine what audio files are in what set.
For more details please refer to the GitHub page

Scene Context-Aware Salient Object Detection
ICCV, Dataset link: https://github.com/SirisAvishek/Scene_Context_Aware_Saliency
This is a new dataset about salient object detection considering the scene context.
For more details please refer to the paper

Tactile Sketch Saliency
ACM MM, Dataset link: https://bitbucket.org/JianboJiao/tactilesketchsaliency/src/master/
This is a new dataset about tactile saliency on sketch data, i.e. measuring which region is more likely to be touched on the object depicted by a sketch. For more details pelase refer to the paper
Attention Shift Saliency Ranks
CVPR/IJCV, Dataset link: https://cove.thecvf.com/datasets/325
This is the first large-scale dataset for saliency ranks due to attention shift.
For more details pelase refer to the project

Task-driven Webpage Saliency
ECCV, Dataset link: https://quanlzheng.github.io/projects/Task-driven-Webpage-Saliency.html
This is the first dataset about webpage saliency modelling according to different tasks, i.e. the attention may shift according to different task when viewing a webpage. For more details pelase refer to the paper

Real Noisy Stereo
IJCV, Dataset link:
https://drive.google.com/file/d/1yjQs_fH7SQ-7pSLigklUkNH96SovghWG/view